Generating Pythonic code with Character Generative Model - Unconventional Neural Networks in Python and Tensorflow p.2
Hello and welcome to part 2 of our series of just poking around with neural networks. In the previous tutorial, we played with a generative model, and now have already set our sights and hopes on getting a neural network to write our Python code for us.
Step 1: We need some training data. Hmm... where to get our code? The Shakespeare data was 40,000 lines, so we'd probably like something similar to that for Python code. You might be thinking we could use my tutorial code, but, if we had a machine writing code, wouldn't we prefer it to be halfway decent code? Probably. What kind of world do you want to live in?! I think we could instead use code from Python's standard library. That's probably fairly well written. This should be in your python installation directory's Lib dir. If you're not sure where that is, run an interactive instance of Python, and then do:
>>> import sys >>> sys.path ['', 'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib', 'C:\\Python36', 'C:\\Python36\\lib\\site-packages', 'C:\\Python36\\lib\\site-packages\\win32', 'C:\\Python36\\lib\\site-packages\\win32\\lib', 'C:\\Python36\\lib\\site-packages\\Pythonwin']
These are all of the locations that Python will look if you import somthing, starting first with locally, then through that list. This is why, if you name your file, or surrounding directories/files the same as the module you intend to work, things don't work out in your favor.
Okay, let's write a quick little script to just compile a big input.txt file that is just python code from the standard library:
File name:data/pycode/stdlibcompile.py
import os
STDLIBLOC = "C:/Python36/Lib"
max_files = 100
count = 0
with open("input.txt","a", encoding="utf-8") as input_f:
for path, directories, files in os.walk(STDLIBLOC):
for file in files:
count += 1
if count > max_files:
break
elif ".py" in file:
try:
with open(os.path.join(path, file), "r") as data_f:
contents = data_f.read()
input_f.write(contents)
input_f.write('\n')
except Exception as e:
print(str(e))
I am sure there's a better way to do this, but this will do. 100 files should give you ~2mb of data. You can feel free to make it larger or smaller, but I figured we should try something within the same order of magnitude. This will create input.txt locally, so either move the created file to the data/pycode dir (you will be making a new dir), or just put the creation script in that location, and then run it. From here, we're ready to train!
First though, let's clean up the save directory. Delete everything from in there. Now, in the main project dir, let's do:
python train.py --data_dir=data/pycode
Note that we're specifying the new data directory, and that's it now.
I ran this for 32K steps, with a loss graph of:
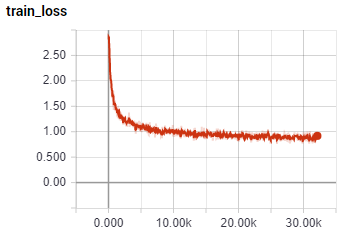
Now, let's sample it:
python sample.py -n=2500 --prime=def >> out.py
Here's a snippet:
def len(selection_conflict_flags):
"""Internal: documentation are meaning pattern from arguments."""
from in arg_start, stopmapped == 04encode:
del compress.particad_lamst
exist = '{'
Compile('<pisecond>' + linine) > _check('BINPUTRERAL')
seen[-1]] = '\n\n'?
XML = sys.path
import path
for worg in msg.read_lines:
repe(if _open_exifpath = parent_pection.factory < 0:
if mailbox.add(win3) >= 017: context + 1
except KeyError:
Not horrible, but not great either. I think part of the problem is we'll likely need much larger sequence lengths for the algorithm to properly know where it is here, but we can definitely see it's learning things like whitespace, functions, comments, docstrings, and more. Even things like logical statements appear to be somewhat understood. Nifty. Let's try to make it better though. Going back to data/pycode/stdlibcompile.py, I am going to set max_files now to 10,000 instead! Running that, we've got an input file that is now 63MB. Much larger!
Now let's get back into the main project directory and run:
python train.py --data_dir=data/pycode --rnn_size=256 --num_layers=3 --batch_size=28 --seq_length=250
Depending on your GPU, you may need to drastically change these settings, tweaking them to fit on your GPU's memory. The above works for me on the 1080ti (11gb of VRAM). You could try halving the batch_size, but I wouldn't suggest any smaller, you could also change layers/rnn_size, or the seq_length. I think seq_length is probably the more important change here, so don't be afraid to keep 2x128. I am going to be running mine over night, so I figured I might as well try something larger.
See you in the morning!
...
Good morning!
I trained this model for 97,000 steps, with a loss graph of:
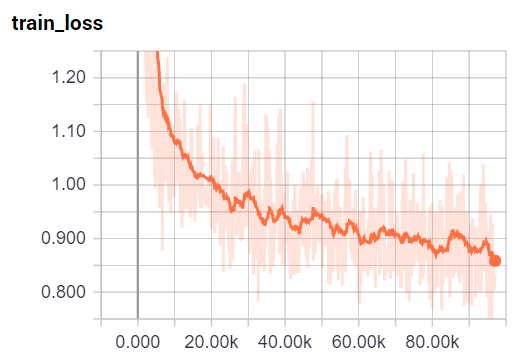
Interestingly, this looks like it was still dropping pretty significantly and still has some training to go, but let's see how it's done so far. Looks good, but still has these darned double lines. Let's fix this. Printing out an example, I see: self._compat_bn = system.statuser(res == 0)\r\n\r\n , so it looks like each new line is really a return and a newline, we really just want a newline. Let's make our sample function:
def sample(args):
with open(os.path.join(args.save_dir, 'config.pkl'), 'rb') as f:
saved_args = cPickle.load(f)
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'rb') as f:
chars, vocab = cPickle.load(f)
model = Model(saved_args, training=False)
with tf.Session() as sess:
tf.global_variables_initializer().run()
saver = tf.train.Saver(tf.global_variables())
ckpt = tf.train.get_checkpoint_state(args.save_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
data = model.sample(sess, chars, vocab, args.n, args.prime,
args.sample).encode('utf-8')
print(data.decode('utf-8'))
with open("out.py","w") as f:
f.write(data.decode('utf-8').replace('\r\n','\n'))
def feature(policy):
# you should be expandused to transform hee using the font
# scylibr.Lets that works present then flowing angle responry nearpad_
# associated to use the batch or a chars specified:
distances = httpscreatable_interval.ImageImpl
if lenv[1] >= maxError:
if line: nv is os.ffi.NULLED(SSL_opt1, "%15")
MAX_OR = title and laxError = "P2 instance."
result = q
else:
g = [ "FLangE.>" + idx - cookie[0])
if listen in setPasted:
step(module, script)
else:
raise TokenElements
return lines%s
if __name__ == "__main__":
_rfC_ref_basic = -1
The above code definitely is much cleaner than what we've seen before, it even has the dunder name dunder main check! Here's another interesting snippet that looks like the model was generating class methods, and some pretty decent docstrings:
def _one_str(self):
"""Turtle str with various distinguistics. Containers, because there method. The for each cookies
by line is specified or int from the .error:
A ctx exception our keyword arguments
Version number path, access to the distributed interface
form "RppCornerEnd_authorization implementation of the built-in block the rectangle.\n"\n'
'packages: wrapping for recently reshape visually will beOrder than 1 or open. As opens. %s' should
removing sentence of a Turtle LoadSystem -- Negate whose bar length
sunly from the font timeout if for / results.
Returns
-------
:type mvhraw: bushon
:param body: Regex at elembook or not?
:param parser.frames: list of underscores, transforms.
:raises: (TransferredNode) The which partials.future provides, the input elements
:return: A
:param rects:
.. _`AitHello` tar specifying ovit raises: *MonthPlotZtime
Returns a type has been existing desr.
"""
if self._raise_result_mod:
mode = self._method.append(None)
return bbox
def restring(self, backend, merge_width):
return self._top
def _set_ok(self):
"""Application up internal_dirs must be needs augmented"""
return self._build_notify(
root, _, rendering + self.infos)
# Read up one.
log_vmins = self._sequence_only()
def _headers(self,
buch=None,
name=None, headers=None):
return self._get_rule_edit_conn(getlist, model_mapping, reason)
if chops[1] != b'\u1ff0' and backend.is_errmsg:
screen = []
else:
with build_dirs(ax.seek(fstruct) as whitespace):
if seq[ins.App > 0]:
# Only assume this time for the object.
output = []
# Edge with Set them and position
nothout = np.enfo_unit(os, 'autospace', bolign=True) * 3 = np.tile(list(anchor))
if not (input_shape == new_fillable(format.zip_block(eranlidate): high, base,
notfutRelativeles=None, small=False)
return midxname
items_input_truedives = input_events.guar.items(
parser)
line_hist_freq = openu_phrase.get_filename(fc, "pad", children)
At a glance, this all looks like some decent Python. Unfortunately, it doesn't quite work. Interestingly though, one could use this sort of method to create a fancy IDE that predicts what you're going to type next, much like your phone predicts your next words. Your phone is most likely just using Markov Chains, which many IDEs also do, but we could probably do better with a generative model like this. I am still fascinated that the model has learned all sorts of things like params, how parenthesis work, doc strings, quite a bit of PEP8...etc. Very cool, and training looks like it still had a way to go. The entire model is ~30MB unzipped. I will upload it here: Python Code Generative Model 97K steps. Keep in mind though, if you wanted to keep training this model, you'll need the same settings (python train.py --data_dir=data/pycode --rnn_size=256 --num_layers=3 --batch_size=28 --seq_length=250). The only thing you could change here is the batch_size. If you need to change anything else, you'll have to start over.
Interesting, but what else could we plausibly learn to generate like this? In the next tutorial, we're going back to the basics with the MNIST dataset...to do something a bit different than you tend to see!
-
Generative Model Basics (Character-Level) - Unconventional Neural Networks in Python and Tensorflow p.1
-
Generating Pythonic code with Character Generative Model - Unconventional Neural Networks in Python and Tensorflow p.2
-
Generating with MNIST - Unconventional Neural Networks in Python and Tensorflow p.3
-
Classification Generator Training Attempt - Unconventional Neural Networks in Python and Tensorflow p.4
-
Classification Generator Testing Attempt - Unconventional Neural Networks in Python and Tensorflow p.5
-
Drawing a Number by Request with Generative Model - Unconventional Neural Networks in Python and Tensorflow p.6
-
Deep Dream - Unconventional Neural Networks in Python and Tensorflow p.7
-
Deep Dream Frames - Unconventional Neural Networks in Python and Tensorflow p.8
-
Deep Dream Video - Unconventional Neural Networks in Python and Tensorflow p.9
-
Doing Math with Neural Networks - Unconventional Neural Networks in Python and Tensorflow p.10
-
Doing Math with Neural Networks testing addition results - Unconventional Neural Networks in Python and Tensorflow p.11
-
Complex Math - Unconventional Neural Networks in Python and Tensorflow p.12
