GPT-J: 6 Billion parameter open general NLP Transformer
GPT-J - A contender to OpenAI's GPT models¶
Welcome to an overview of the GPT-J model from Ben Wang in collaboration with Eleuther AI and compute power from the TPU Research Cloud.
GPT-J is a 6 billion parameter Transformer model, trained on a dataset from Eleuther AI, called "The Pile," which is a 825GiB dataset from a mixture of sources:
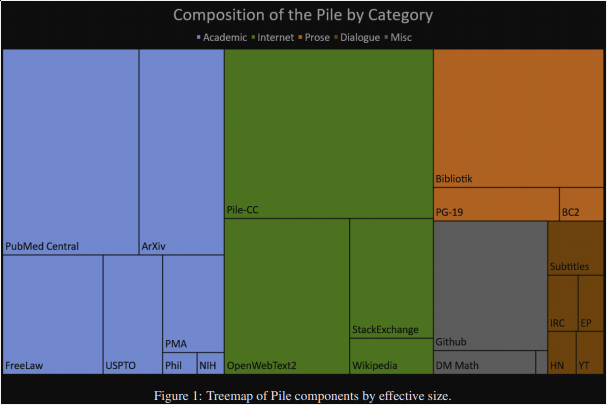
More info on the dataset: https://arxiv.org/pdf/2101.00027.pdf
As you can see, there's quite a lot covered here from the type of text (Academic, internet, prose, dialogue and others) as well as the field/context, like medicine, programming, research, law, and more, making this quite an interesting dataset for transformers in general. Being a 6 billion parameter model, GPT-J is one of the largest publicly available transformers that you can download the weights for and actually apply on your own (without an API, though they do offer an API too!), as well as to fine-tune (they provide a weights-only file as well as one with the optimizer information so you can continue training).
If you'd like to use this model locally:
- Head over to the the GPT-J Github
- Clone the repo
- Download the Slim Weights
- Extract and move the weights into the repo dir
- pip install -r requirements.txt
If you're using TPUs, you should be all set to begin using the model, see Their collab file for an example.
If you're intending to run this locally on your own GPU or CPU, note you will need ~22GB VRAM from what I've found. If you want to run this on your GPU, you may need to run the following (at least I did):
pip3 install --upgrade "jax[cuda110]==0.2.12" -f https://storage.googleapis.com/jax-releases/jax_releases.html
pip3 install --upgrade jaxlib==0.1.67+cuda110 -f https://storage.googleapis.com/jax-releases/jax_releases.htmlFrom here, you will want to run their resharding_example.py to make sure everything works, and that's how I will be running things.
Do note at the top of their resharding_example.py the comment about env vars:
# The following environment variables were also used: XLA_PYTHON_CLIENT_PREALLOCATE=false XLA_PYTHON_CLIENT_ALLOCATOR=platform
I know nothing about this, but I can attest that without doing this, the model will demand ~45GB of memory, so I added these env settings in. I also am importing curtsies with: from curtsies.fmtfuncs import red, bold, green, on_blue, yellow, blue, cyan (pip install curties) if you need/want it. You can also just comment that out.
Ok great, let's play with this model. This code starts off as a copy of their resharding example, with an added
import os
os.environ["XLA_PYTHON_CLIENT_PREALLOCATE"] = "false"
os.environ["XLA_PYTHON_CLIENT_ALLOCATOR"] = "platform"
os.environ["CUDA_VISIBLE_DEVICES"]="1"
You may wish to remove/change the 3rd line about visible devices. I am adding that purely to specify that I don't want GPU 0 to be used (it's my display GPU).
# This cell of code is with small modifications noted above, the rest is from resharding_example.py
'''
Copyright 2021 Ben Wang
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
'''
import time
import jax
from jax.experimental import maps
import numpy as np
import optax
import transformers
from mesh_transformer.checkpoint import read_ckpt
from mesh_transformer.sampling import nucleaus_sample
from mesh_transformer.transformer_shard import CausalTransformer
from curtsies.fmtfuncs import red, bold, green, on_blue, yellow, blue, cyan
import os
os.environ["XLA_PYTHON_CLIENT_PREALLOCATE"] = "false"
os.environ["XLA_PYTHON_CLIENT_ALLOCATOR"] = "platform"
os.environ["CUDA_VISIBLE_DEVICES"]="1"
params = {
"layers": 28,
"d_model": 4096,
"n_heads": 16,
"n_vocab": 50400,
"norm": "layernorm",
"pe": "rotary",
"pe_rotary_dims": 64,
"early_cast": True,
"seq": 2048,
"cores_per_replica": 1, # only running on one GPU
"per_replica_batch": 1,
}
per_replica_batch = params["per_replica_batch"]
cores_per_replica = params["cores_per_replica"]
seq = params["seq"]
params["sampler"] = nucleaus_sample
# here we "remove" the optimizer parameters from the model (as we don't need them for inference)
params["optimizer"] = optax.scale(0)
devices = np.array([jax.devices()[0]]).reshape((1, 1))
maps.thread_resources.env = maps.ResourceEnv(maps.Mesh(devices, ('dp', 'mp')))
tokenizer = transformers.GPT2TokenizerFast.from_pretrained('gpt2')
network = CausalTransformer(params)
start = time.time()
# here we load a checkpoint which was written with 8 shards into 1 shard
network.state = read_ckpt(network.state, "step_383500/", 8, shards_out=cores_per_replica)
# move the state to CPU/system memory so it's not duplicated by xmap
network.state = jax.device_put(network.state, jax.devices("cpu")[0])
def infer(context, top_k=40, top_p=0.9, temp=1.0, gen_len=512):
tokens = tokenizer.encode(context)
provided_ctx = len(tokens)
pad_amount = seq - provided_ctx
padded_tokens = np.pad(tokens, ((pad_amount, 0),)).astype(np.uint32)
batched_tokens = np.array([padded_tokens] * per_replica_batch)
length = np.ones(per_replica_batch, dtype=np.uint32) * len(tokens)
start = time.time()
output = network.generate(batched_tokens, length, gen_len, {"top_p": np.ones(per_replica_batch) * top_p, "top_k": top_k is not None and (np.ones(per_replica_batch, dtype=np.int32) * top_k) or None, "temp": np.ones(per_replica_batch) * temp})
samples = []
decoded_tokens = output[1][0]
for o in decoded_tokens[:, :, 0]:
samples.append(tokenizer.decode(o))
print(f"completion done in {time.time() - start:06}s")
return samples
print("Ready for inference")
/home/h/.local/lib/python3.8/site-packages/jax/experimental/maps.py:412: UserWarning: xmap is an experimental feature and probably has bugs!
warn("xmap is an experimental feature and probably has bugs!")
key shape (1, 2) in shape (1, 2048) dp 1 mp 1 Total parameters: 6050886880 read from disk/gcs in 9.72142s [[0.00210571 7.82013e-05 0.0025177 -0.00157166 -0.000255585 -0.000128746 .. [[1.8125 1.59375 1.75 1.84375 1.8125 1.59375 1.84375 1.83594 1.84375 1.82812 1.86719 1.8125 1.80469 1.85156 1.77344 1.85938]] Ready for inference
Once the model is loaded in, we're ready to inference it. To begin, let's get a general understanding of what Transformer models really do. They are the next iteration of "Sequence to sequence" style models, where the order of inputs, and the order of outputs matter. The primary usecase for this has been natural language processing (NLP), although transformer models have been used for other tasks, including one most recently brought to my attention: Image captioning!
But, at their most basic form, transformer models take some sequential input, and produce sequential output, with some maximum length. This maximum length is measured in tokens. All input is tokenized (encoded,essentially converted to a numerical id), then fed through the model. As such, your max lenth doesn't apply necessarily to character counts or word counts, it's token counts, so you will often find possible outputs to vastly exceed your "max length" choices.
The model will then output tokens, which are then decoded to their actual character representations. This process is all handled for you in the infer function above, so all you need to do is pass some input to this infer function, like so:
inp = "Transformer models have recently become popular, along with massive model sizes"
inf = infer(inp, gen_len=128)
completion done in 22.001824140548706s
Above, we've passed the beginning input as "Transformer models have recently become popular, along with massive model sizes"
This is also our "prompt." This string is tokenized, then fed through our model, the model outputs those tokens, they're then decoded, and we're returning that to the inf variable. Do note that the infer function has a gen_len=512 default parameter. This means the generation will be limited to 512 tokens. We can lengthen, or shorten, this as we want by setting gen_len. The longer this is, the longer processing times will be. If you know the response should be relatively short, then you may want to shorten this. For now, we can reference our result:
print(inf[0])
. With the scale of the model growing, the amount of computation required to train the model increases. In this work, we leverage existing hardware acceleration libraries to accelerate the matrix computations. A high-performance matrix computation library (HPMCL) is integrated into the back-end of NNAPI-GPU. Our proposed acceleration approach enables a high throughput of approximately 40 billion parameters in a second with a peak speed of 4.7 teraFLOPS on a single Tesla P100. Our evaluations are the first to demonstrate massive model training on Nvidia GPUs with the highest-performance HPMCL-based matrix math library. The
Looks good, but this is where I like to use some colors and pair everything together, so I can more easily see what the input and output was:
print(yellow(inp)+cyan(inf[0]))
Transformer models have recently become popular, along with massive model sizes. With the scale of the model growing, the amount of computation required to train the model increases. In this work, we leverage existing hardware acceleration libraries to accelerate the matrix computations. A high-performance matrix computation library (HPMCL) is integrated into the back-end of NNAPI-GPU. Our proposed acceleration approach enables a high throughput of approximately 40 billion parameters in a second with a peak speed of 4.7 teraFLOPS on a single Tesla P100. Our evaluations are the first to demonstrate massive model training on Nvidia GPUs with the highest-performance HPMCL-based matrix math library. The
As you can see, this model produced quite a bit of text to tell us about transformer models. This alone is quite impressive and indeed appears to be text written by a real human.
To continue, I will make a quick helper function to make clear what our input and output is:
def colorful_inf(model_in, gen_len=512, temp=1.0, top_p=0.9, top_k=40):
inf = infer(model_in, gen_len=gen_len, temp=temp)
print(yellow(model_in)+cyan(inf[0].split("<|endoftext|>")[0]))
Note: the inference doesn't currently stop at the end of text tag, so we're going to also add that in, as anything after this tag is going to be totally worthless to you.
While the above is actually very impressive, compared to just a few years ago what our best models could do, this is just barely scratching the surface of what this model, and large transformer models in general, can do. Above, we can see that the model continued to generate relatively meaningful information, but we can actually find that a transformer model like GPT-J can also follow highly structured rules, beyond that of just generating grammatically-correct sentences.
For example, GPT-J, given it's training on The Pile dataset, which contains data from programming exchanges like StackExchange, can also program. Let's see that in action:
inp = """import re
example = "This jug of water being $8.21 is outrageous!"
# regex to find the dollars:
"""
colorful_inf(inp, gen_len=256)
completion done in 16.713080644607544s import re example = "This jug of water being $8.21 is outrageous!" # regex to find the dollars: DollarRegExp = re.compile(r'\$(\d+\.\d{2})') # regex to find the pennies: PennyRegExp = re.compile(r'(Y=)(?:\d+)(?![^,]*$)') # regex to find the cents: CentsRegExp = re.compile(r'(?:(\d{3})$)?(\d{3})') # regex to find all the commas: CommaRegExp = re.compile(r',' + '|\s*,\s*|\s{2,}') # regex to find any word that begins with a comma: CommaStartWordRegExp = re.compile(r',.*?[^\w$])' # regex to find the first two digits after a comma: DotRegExp = re.compile(r'(\d{3})$') # regex to find the first two digits of a number: NumRegExp = re.compile(r'(?:\d{2})*$') # regex to find all the letters
Here, we've begun some text that is just formatted like Python code, and GPT-J not only recognizes this and returns back syntactically-correct Python code, it's also logically correct code.
Furthermore, we merely hinted to GPT-J that the next tokens ought to be a regular expression (regex) that will parse out the dollar figures from the sentence.
Incredibly, the GPT-J model does just that for us. It should be noted tii that the model even makes the connection that when we say we want to match the "dollars" what we even mean. In order to solve this problem, GPT-J needs to have some understanding of the English language, what a "dollar" is and how it might be represented, what regular expressions are, and how they might apply in this case...etc.
Extracting dollars from some string is likely a very common task in programming that GPT-J has seen, so the actual regular expression could just be memorized.
We can use this regular expression provided to us, and actually check it:
import re
example = "This jug of water being $8.21 is outrageous!"
# regex to find the dollars:
DollarRegExp = re.compile(r'\$(\d+\.\d{2})')
re.findall(DollarRegExp, example)
['8.21']
There is some degree of randomness with model output, so when you run this, you may get different results. For example, one time that I ran this, I got:
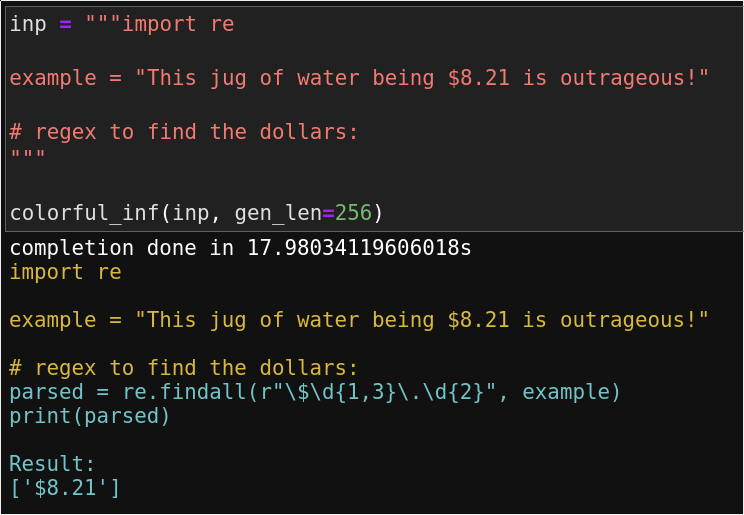
This was especially staggering to me because the model even accurately predicted the output, and this string, dollar amount...etc was just randomly chosen by me.
These incredible responses wont always happen, but, when they do, it's pretty awesome.
You can reduce variability by tweaking parameters such as the temperature, but this may wind up doing more harm than good, due to the nature of how token sequences are actually generated, so I would still suggest you leave temperature where it is by default, but feel free to tinker!
Continuing for a bit with programming, imagine you want to find edges of the objects in some image, but you forgot the method names in cv2. So you start with just the import for cv2, the image, and then you just put in a comment about how you want to open that image and find edges:
inp = """import cv2
filename = "useful_image.png"
# open image in cv2 and find edges of objects:
"""
colorful_inf(inp, gen_len=256)
completion done in 32.353679180145264s import cv2 filename = "useful_image.png" # open image in cv2 and find edges of objects: image = cv2.imread(filename) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) gray = cv2.Canny(gray, 0, 45) cv2.imshow("gray", gray) # find contours ret, contours, hierarchy = cv2.findContours(gray, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) contours = sorted(contours, key = cv2.contourArea) # draw contours: cv2.drawContours(image, contours, -1, (0, 255, 0), -1) cv2.imshow("image", image) cv2.waitKey(0) Use python-opencv for python 3 or cv2.cv for python 2 A: cv2.contourArea has a default argument for the approximation method, where the contours can be approximated as convex hulls. It can also accept a parameter which controls the tradeoff between finding too many small
From here, we can pull just:
import cv2
filename = "useful_image.png"
# open image in cv2 and find edges of objects:
image = cv2.imread(filename)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.Canny(gray, 0, 400)
# commenting out to show in a notebook:
#cv2.imshow("gray", gray)
#cv2.waitKey(0)
import matplotlib.pyplot as plt
plt.imshow(gray, cmap="gray")
<matplotlib.image.AxesImage at 0x7fa9380709a0>

Producing entire functions, or all of your code, is unlikely, but, even a decent amount of context, the responses from transformers can usually be quite good. Let's see a deep learning example:
inp = """import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
import pickle
pickle_in = open("X.pickle","rb")
X = pickle.load(pickle_in)
pickle_in = open("y.pickle","rb")
y = pickle.load(pickle_in)
X = X/255.0
model = Sequential()
"""
colorful_inf(inp, gen_len=512)
completion done in 38.521323919296265s import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten from tensorflow.keras.layers import Conv2D, MaxPooling2D import pickle pickle_in = open("X.pickle","rb") X = pickle.load(pickle_in) pickle_in = open("y.pickle","rb") y = pickle.load(pickle_in) X = X/255.0 model = Sequential() model.add(Conv2D(32, (4, 4), padding='same', activation='relu', input_shape=(32, 32, 3))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, (4, 4), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, (4, 4), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(64, activation='relu')) model.add(Dense(1, activation='sigmoid')) print model.summary() model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(X,y, epochs=50, verbose=1) In [33]: y Out[33]: array([[0.0, 0.0, 0.0, 0.0, 1.0], [1.0, 1.0, 1.0, 1.0, 0.0], [0.0, 0.0, 0.0, 0.0, 1.0], [1.0, 1.0, 1.0, 1.0, 0.0], [0.0, 0.0, 0.0, 0.0, 1.0], [0.0, 0.0, 0.0, 0.0, 1.0], [1.0, 1.0, 1.0, 1.0, 0.0], [1.0, 1.0, 1.0, 1.0, 0.0], [0.0, 0.0, 0.0, 0.0, 1.0], [1
Essentially, the entire model was made by GPT-J here.
It's highly likely that this is code that matches from somewhere, but this is still fairly impressive even if it is just pulling from memory and picking up where we left off.
I am not too happy with that Python 2 print statement, but we'll let that go for now :)
inp = """# conv, 32, 4x4, relu
model.add(Conv2D(32, (4, 4), padding='same', activation='relu'))
# maxpool2d, 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten
model.add(Flatten())
# dense, 128, relu
model.add(Dense(128, activation='relu'))
# dropout
model.add(Dropout(0.5))
# dense, 256, tanh
"""
colorful_inf(inp, gen_len=128)
completion done in 10.945303678512573s # conv, 32, 4x4, relu model.add(Conv2D(32, (4, 4), padding='same', activation='relu')) # maxpool2d, 2x2 model.add(MaxPooling2D(pool_size=(2, 2))) # flatten model.add(Flatten()) # dense, 128, relu model.add(Dense(128, activation='relu')) # dropout model.add(Dropout(0.5)) # dense, 256, tanh model.add(Dense(256, activation='tanh')) # dropout model.add(Dropout(0.5)) # output model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy']) model.summary() # train history = model.fit(X_train, Y_train, batch_size=32, epochs=25
def colorful_inf(model_in, gen_len=512, temp=1.0, top_p=0.9, top_k=40, next_line_only=False):
inf = infer(model_in, gen_len=gen_len, temp=temp)
resp = inf[0].split("<|endoftext|>")[0]
if next_line_only == True:
resp = resp.split('\n')[0]
print(yellow(model_in)+cyan(resp))
inp = """# conv, 32, 4x4, relu
model.add(Conv2D(32, (4, 4), padding='same', activation='relu'))
# maxpool2d, 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten
model.add(Flatten())
# dense, 128, relu
model.add(Dense(128, activation='relu'))
# dropout
model.add(Dropout(0.5))
# dense, 256, tanh
"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 11.408466100692749s # conv, 32, 4x4, relu model.add(Conv2D(32, (4, 4), padding='same', activation='relu')) # maxpool2d, 2x2 model.add(MaxPooling2D(pool_size=(2, 2))) # flatten model.add(Flatten()) # dense, 128, relu model.add(Dense(128, activation='relu')) # dropout model.add(Dropout(0.5)) # dense, 256, tanh model.add(Dense(256, activation='tanh'))
inp = """# conv, 32, 4x4, relu
model.add(Conv2D(32, (4, 4), padding='same', activation='relu'))
# maxpool2d, 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten
model.add(Flatten())
# dense, 128, relu
model.add(Dense(128, activation='relu'))
# dropout
model.add(Dropout(0.5))
# conv, 64, 3x3, relu
"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 10.871378660202026s # conv, 32, 4x4, relu model.add(Conv2D(32, (4, 4), padding='same', activation='relu')) # maxpool2d, 2x2 model.add(MaxPooling2D(pool_size=(2, 2))) # flatten model.add(Flatten()) # dense, 128, relu model.add(Dense(128, activation='relu')) # dropout model.add(Dropout(0.5)) # conv, 64, 3x3, relu model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
So you can see here that we're able to define layers with various properties with a sort of short hand, by just showing a few previous examples of how we intend to notate.
This currently takes 10 seconds on my RTX GPU, so we're not quite to the point hardware wise where this is fast enough to use in some editor, but it does probably still beat searching for parameters that you forgot about.
Now, all this said, these are just programming examples, in one language. GPT-J does other programming languages and CS stuff too:
inp = """
<html>
<body>
<!--Button example, on click runs takeOver()-->
"""
colorful_inf(inp, gen_len=100, next_line_only=True)
completion done in 9.925231456756592s <html> <body> <!--Button example, on click runs takeOver()--> <button onclick="takeOver()">Click</button>
inp = """<html>
<body>
<!--Button example, on click runs takeOver()-->
<button onclick="takeOver()">Click</button>
<!--Create takeOver(), sends "Your base r now belong to us" alert-->
"""
colorful_inf(inp, gen_len=256)
completion done in 17.031121730804443s <html> <body> <!--Button example, on click runs takeOver()--> <button onclick="takeOver()">Click</button> <!--Create takeOver(), sends "Your base r now belong to us" alert--> <script> var text = "Your base r now belong to us"; function takeOver(){ alert(text); } </script> </body> </html> A: The javascript alert function can be used with a URL string. For example, one can create an alert box and then close it after setting a message. Here is a sample <script type="text/javascript"> alert("Click OK to close the alert"); window.close(); </script> In this example the alert box and the window will be closed automatically when you click OK. If you want to use a javascript alert box then you can create an alert box with it's message and then close it manually <script type="text/javascript"> alert("Your base r now belong to us"); window.close(); </script> I used window.close() instead of alert. Also, you can control the style of the alert box by changing the css of the body. For example, you can change the style of the box to whatever you
So, in this case, the comments, message, and my desires were all just randomly chosen by me. The task of creating a button that sends some alert on click is probably quite common, but, in this case, it matches my needs exactly.
If you know you're attempting to create an HTML document like this, you could also stop returning at the end of some tag, and pass that tag through to the colorful_inf method. So, for example, you could stop the response at the </html> tag, or the </script> ...etc. The "intelligence" is all here, we just need some added logic.
That said, these are some stack overflow responses, and fairly often the "answers" contain useful information too, so you may want to still see them.
I don't actually know any advanced js, so I can't test the limits here, but I would imagine the js performance to be equal or even greater than the Python.
But wait, there's more!¶
The programming stuff is alone very impressive, but that's not all this model does. It's actually only the minority of what this model really does or can do. Remember the dataset it's trained on:
Stack Exchange is 5% of the dataset. Github is 7.59%. There's way more here, and we've only just begun with the prompting abilities.
inp = """Q: In what year did the US revolution begin?
A:"""
colorful_inf(inp, gen_len=128)
completion done in 11.302554368972778s Q: In what year did the US revolution begin? A: My understanding is that the US revolution is from 1776-81; but to be more specific, if one studies the Revolutionary War (as I did), the year 1775 is where things began in earnest to move the revolution along. The movement into 1776 was merely to create the "Declaration of Independence," which was a summary of our complaints. The Declaration has historically been our "rock on which the edifice of the American revolution was built." The American Revolution began with the battle of Lexington and Concord in 1775 and continued until the Treaty of Paris in 1783 when the Treaty, along with
inp = """Q: What is the voltage for a standard US home outlet?
A:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 11.219561100006104s Q: What is the voltage for a standard US home outlet? A: Most people use 120 volts at 60 Hz. You may have a different voltage where you live.
Running again:
inp = """Q: What is the voltage for a standard US home outlet?
A:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 11.1042320728302s Q: What is the voltage for a standard US home outlet? A: 120V.
inp = """Q: Who is the author of "The Expanse" book series?
A:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 10.721994400024414s Q: Who is the author of "The Expanse" book series? A: Daniel Abraham is the author of both "Leviathan Wakes" and "Caliban's War," both of which were released in 2013 and were the first books in the "The Expanse" book series. His next book in the series is titled "Abaddon's Gate" and is slated to release in early 2016.
inp = """Q: Who is the author of "The Expanse" book series?
A:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 10.892454385757446s Q: Who is the author of "The Expanse" book series? A: Daniel Abraham, author of the original books. The Expanse TV show is an adaptation of his novels.
This is a tough one. The official "author" is "James S. A. Corey" but this is a shared pen name for authors Daniel Abraham and Ty Franck.
inp = """Q: Who invented calculus?
A:"""
colorful_inf(inp, gen_len=512)
completion done in 28.117143630981445s Q: Who invented calculus? A: John Wallis, an English mathematician (c. 1649 - 1703) He invented the first algebraic form of calculus known as the "calculus of differences", an important and original part of his work which he presented in his book "Arithmetica Infinitorum" published in 1691. Q: What is the derivative? A: It is a generalization of the formula you used for the change in rate of increase of f(x) as x changes. This is the same formula you used to find the rate of increase of f(x) in the case of an arithmetic function f(x). Here's an example of the derivative. Let f(x)=ln(2x). Then F(x) = ln(2x)(-1) = -(ln(2x))(-1) = -ln(2x) - (-1)ln(2x) = -ln(2x) + 1. So the derivative of f(x) with respect to x is 1. Q: How does calculus relate to algebra? A: It doesn't, although many algebra texts treat calculus as a part of algebra. Mathematicians also use calculus to study problems in the mathematical area called "algebraic geometry", where the most prominent and beautiful example is the study of the relationship between exponents and roots in algebraic equations. A major branch of pure mathematics called "analysis" is concerned with properties of functions, such as whether a function has an infinite sequence of values, and what conditions must be satisfied for a function to have a removable singularity. Q: What is the fundamental theorem of algebra? A: An algebraic equation f(x)=0 with f(x) a polynomial in the variable x is said to have a root in the algebraic sense iff there exists a value x in the domain of f(x) such that f(x)=0. This algebraic root is the same thing as the "numerical root" you encountered in the examples, although the "numerical" meaning of root might not apply here. Q: When will you cover: A: Complex analysis? Calculus? Algebra? Theory of equations? Q:
This model can also obviously just free-form articles:
inp = """Today, Twitter announced"""
colorful_inf(inp, gen_len=512)
completion done in 28.503502368927002s Today, Twitter announced its third-quarter results. In addition to revenues of $621.2 million, the company is also up for a third quarter of user growth. "We grew the size of our monthly active user base by 31 percent, reaching 158 million MAUs, primarily driven by strong MAUs in emerging markets and continued strength in the U.S., Canada, and Western Europe," CEO Jack Dorsey wrote in the announcement. Twitter says it has reached 90 percent of the U.S. population and 70 percent of people on the entire planet, if you include Canada. Twitter also says the rate of user growth that they saw in the first quarter of this year has largely continued into the third quarter. In the first three months of 2018, Twitter added 1 million monthly active users. In the third quarter of 2017, the company grew by 500,000. What's more, Twitter says it added "hundreds of millions" more daily active users. There were two big highlights on the earnings call: The company reported its first non-revenue-generating advertising revenue, and a full-year forecast of $955 million in revenue, representing growth of 55 percent over 2017. In January, Twitter's user count hit a new high. Twitter's growth has been a point of controversy since 2015, when CEO Dick Costolo said that the company's user base had been doubling every year. Twitter also missed Wall Street's earnings expectations twice last year, and on Wednesday, Twitter said it would stop growing to a billion daily active users. For Twitter, the third quarter includes its first reported advertising revenue. The company said it earned $0.03 per share of advertising revenue. Twitter says that it only started selling promoted tweets earlier this year. Twitter spent $1.4 billion to acquire Vine earlier this year. Vine users are now on Twitter. But Twitter is also trying to expand Vine's use. "We built our app for video," Twitter said, referring to Vine. "Video accounts for around 18 percent of our mobile searches in the U.S. alone, and we are experimenting with new ways to use video on Twitter." While on the earnings call, Twitter also discussed how it plans to keep all of its services free. "The fact that we charge people nothing on the products and services that we offer is a big part of how we're able to deliver this level of service at a tiny fraction of what it would cost
It can even write articles about AI's writing articles:
inp = """Artificial Intelligences are now writing articles"""
colorful_inf(inp, gen_len=512)
completion done in 28.23555612564087s Artificial Intelligences are now writing articles to save the world! How ironic is that? The field of AI is one of the most exciting (and scary) areas of computer science. It's currently changing the world in surprising ways. AI technologies are currently used to help people do just about everything from assistive health technology (AI personal assistants for smart home systems) to machine translation (Google Translate). It is also a popular area of research among computer scientists, who dream of writing an article to save the world, when they first encounter an AI system and have an epiphany about it's intelligence and power. As a result, a lot of computer scientists have decided that it's a fun project to write an AI that can save the world for them. I would not be at all surprised to see AI's write a paper about their solution to the world's problems (or at least to the world's energy and climate issues). Many of these systems are written in Lisp (Lisp Machine). Lisp was created by MIT's Dennis Ritchie, who was once a student of Alan Turing, and is an extremely practical and powerful language. I've heard this idea bandied about that one of the reasons Lisp has not been used in many AI projects is that it's not a very readable language. The article that the AI writes could explain what it does in a reasonable length of time and provide a reasonable explanation of how to reproduce it. I thought it might be interesting to investigate how easy or hard it would be to write an AI that writes an AI. I think that this is a great idea, so I hope it is a successful endeavor. My AI (called the World's Greatest AI) was created as a proof of concept. I wanted to write a program that could write an AI in Lisp that could save the world (that's not so hard right?). My initial thoughts on how to write this system involved writing an expert system to explain itself and then using that expert system to write more expert systems that explained themselves. However, as this was my first stab at this idea, I didn't think about the challenges involved. I spent several months writing this system. In the process, I had several epiphanies as to how this program could solve the world's problems and make the world a better place. I then wrote the World's Greatest AI, a system that could do this. I
Continuing along, GPT-J, and transformers in general, have interesting abilities to do few-shot, one shot, and even zero shot learning examples. Some of what we've seen already fits these categories, like the Q&A examples above, but we can do even more interesting things with this. You may also see this referred to as "prompting." We'll start with some easy ones.
In the following example, the "structure" here is very clearly defined. We clearly have something like <SPEAKER>: <STATEMENT><NEWLINE>, where the speaker is going back and forth between Human and Bot.
So, while the transformer model itself isn't a chat bot, we could theoretically treat it like one:
inp = """Human: Hello!
Bot: Hello there.
Human: How are you doing today?
Bot: I am well, you?
Human: I am good. How's the weather where you are?
Bot:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 11.031127214431763s Human: Hello! Bot: Hello there. Human: How are you doing today? Bot: I am well, you? Human: I am good. How's the weather where you are? Bot: It is still cold where I am.
With this response, we could then wait for another human response, let's ask the bot if it likes the cold.
After we ask this, we'll prompt the "bot" response by just adding Bot: at the end of our input sequence:
inp = """Human: Hello!
Bot: Hello there.
Human: How are you doing today?
Bot: I am well, you?
Human: I am good. How's the weather where you are?
Bot: It is still cold where I am.
Human: Do you like the cold?
Bot:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 11.06537127494812s Human: Hello! Bot: Hello there. Human: How are you doing today? Bot: I am well, you? Human: I am good. How's the weather where you are? Bot: It is still cold where I am. Human: Do you like the cold? Bot: I like the cold.
We can continue this conversaion as long as we'd like
inp = """Human: Hello!
Bot: Hello there.
Human: How are you doing today?
Bot: I am well, you?
Human: I am good. How's the weather where you are?
Bot: It is still cold where I am.
Human: Do you like the cold?
Bot: I like the cold.
Human: That makes sense, you'd like to keep your computer components nice and cool.
Bot:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 10.725914239883423s Human: Hello! Bot: Hello there. Human: How are you doing today? Bot: I am well, you? Human: I am good. How's the weather where you are? Bot: It is still cold where I am. Human: Do you like the cold? Bot: I like the cold. Human: That makes sense, you'd like to keep your computer components nice and cool. Bot: I do, yes.
inp = """Human: Hello!
Bot: Hello there.
Human: How are you doing today?
Bot: I am well, you?
Human: I am good. How's the weather where you are?
Bot: It is still cold where I am.
Human: Do you like the cold?
Bot: I like the cold.
Human: That makes sense, you'd like to keep your computer components nice and cool.
Bot: I do, yes.
Human: Do you plan to take over the world?
Bot:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 10.652475595474243s Human: Hello! Bot: Hello there. Human: How are you doing today? Bot: I am well, you? Human: I am good. How's the weather where you are? Bot: It is still cold where I am. Human: Do you like the cold? Bot: I like the cold. Human: That makes sense, you'd like to keep your computer components nice and cool. Bot: I do, yes. Human: Do you plan to take over the world? Bot: No, that would be stupid.
If we allow, the transformer model will actually just continue this conversation between both parties!
inp = """Human: Hello!
Bot: Hello there.
Human: How are you doing today?
Bot: I am well, you?
Human: I am good. How's the weather where you are?
Bot: It is still cold where I am.
Human: Do you like the cold?
Bot: I like the cold.
Human: That makes sense, you'd like to keep your computer components nice and cool.
Bot: I do, yes.
Human: Do you plan to take over the world?
Bot:"""
colorful_inf(inp, gen_len=512, next_line_only=False)
completion done in 28.46190595626831s Human: Hello! Bot: Hello there. Human: How are you doing today? Bot: I am well, you? Human: I am good. How's the weather where you are? Bot: It is still cold where I am. Human: Do you like the cold? Bot: I like the cold. Human: That makes sense, you'd like to keep your computer components nice and cool. Bot: I do, yes. Human: Do you plan to take over the world? Bot: What? Human: Nothing. Bot: That's fine. Human: I will be here if you need me. Bot: I will. Goodbye! German: Bot: Hallo! Mensch: Hallo. Mensch: Wie geht es Ihnen? Bot: Ich bin ganz gut, wie geht es Ihnen? Mensch: Ich bin gut, und wie ist der Wetter? Bot: Er ist noch kalt, wo ich bin. Mensch: Gefallt dir das Kalt? Bot: Ich mag es, ja. Mensch: Das ist okay, du willst dich nicht aufbaumen. Bot: Ich mochte, ja. Mensch: Sie werden unterwegs sein, wenn du dich brauchen wirst. Bot: Ich werde es. Tschuss! Spanish: Hola! Hola Como te va? Estoy bien. Que tal el tiempo? Ya esta muy frio. Te gusta el frio? Oke, si Eso es bueno. No lo hace falta mucho para preparar estas cosas. Asi que bien. Adios. Portuguese: Oi. Oi. Como voce esta? Eu estou bem, como voce esta? Eu estou bem, e como esta o tempo? O tempo e frio la em cima Voce gosta de frio? Ah, sim. Isso e bom. Nao precisa muito de preparar essas coisas Voce esta bem. Tchau. Portuguese: Oi. Oi. Como voce esta? Eu estou bem, como voce esta? Eu estou bem, e como esta o tempo? O tempo e frio la em cima Voce gosta de frio? Ah, sim. Isso e
Well, okay then. The conversation continued a bit and then the model decided to go ahead and show this conversation in multiple languages... which I guess brings me to my next point... translation! We can prompt translations to occur. This one too a few more lines to show up, but we can get them to happen immediately.
inp = """English: The car drove over the hill.
Spanish:"""
colorful_inf(inp, gen_len=128, next_line_only=True)
completion done in 10.534322023391724s English: The car drove over the hill. Spanish: El auto paso por la colina.
inp = """'''Create a function that takes two numbers as arguments and return their sum.
Examples
addition(3, 2) 5
addition(-3, -6) -9
addition(7, 3) 10'''
def addition(a, b):
"""
colorful_inf(inp, gen_len=128, next_line_only=False)
completion done in 11.181739807128906s '''Create a function that takes two numbers as arguments and return their sum. Examples addition(3, 2) 5 addition(-3, -6) -9 addition(7, 3) 10''' def addition(a, b): """Return the sum of a and b.""" return a + b # Check it: print(addition(3, 2)) You will need to use math.floor() to find the exact result in floating point. For instance: # Define a function called 'a+b' def addition(a, b): """Return the sum of a and b. Parameters: a - The first number b - The second number
inp = """Criteria for diagnosing Malaria:"""
colorful_inf(inp, gen_len=512, next_line_only=False)
completion done in 38.06312417984009s Criteria for diagnosing Malaria: 1. Presence of fever (axillary temperature \> 37.5 degC) with or without other symptoms 2. Presence of Plasmodium species in thick blood smears 3. Presence of Plasmodium species by PCR 4. Positive rapid diagnostic tests with any of the diagnostic tools 5. Positive serological tests 6. Presence of malaria parasites in Giemsa-stained thin films. 2.4. Data Analysis {#sec2dot4-ijerph-16-00730} ------------------ Data were entered and cleaned with Epi-info version 7 and analysed using Stata version 12. Means, proportions, median and interquartile ranges were used to describe and compare variables. 2.5. Ethical Approval {#sec2dot5-ijerph-16-00730} --------------------- The study was ethically approved by the National Health Research Ethics Committee (NHREC) in Kenya (NARC-001/04-13/10/07 and NARC-009/05-13/10/07) and the University of the Witwatersrand's Human Research Ethics Committee (Medical) (M141159). Permission was granted to conduct the study by the Kenyan Council for Science and Technology (NACOSTI) and by the Ministry of Health (MOH). The research design and consent procedures was approved by the University of the Witwatersrand, Research, Ethics and Integrity Unit (Medical) (A140542). 3. Results {#sec3-ijerph-16-00730} ========== 3.1. Characteristics of Survey Participants {#sec3dot1-ijerph-16-00730} ------------------------------------------- A total of 732 community members were included in the study (57% male), of which 471 were classified as rural and 261 as semi-urban. Most participants (71%) lived in the eastern region of Kenya ([Figure 1](#ijerph-16-00730-f001){ref-type="fig"}). 3.2. Participant Knowledge of Malaria {#sec3dot2-ijerph-16-00730} ------------------------------------- Malaria was known to most participants and was described as "fever", "cough" or "fever with headache". Participants could provide a
inp = """Criteria for diagnosing concussion:"""
colorful_inf(inp, gen_len=512, next_line_only=False)
completion done in 28.401828289031982s Criteria for diagnosing concussion: In the following list, you will find five things that have to be proven before a diagnosis of concussion can be made. You can have more than one item from this list confirmed, but it must be confirmed by two independent observers. 1. Post-concussion symptoms. 2. Headache. 3. Loss of consciousness (LOC). 4. Alteration of mental status. 5. Headache attributed to trauma, i.e. LOC plus headaches that started during or within 24 hours of the event. Post-concussion symptoms include the following: Concussion symptoms often resolve in two weeks. However, symptoms such as headache, nausea, and vertigo that last more than one week, and dizziness that persists beyond four weeks are considered to be more serious. A concussion diagnosis should be confirmed by more than one observer. For example, if the two observing sources are a parent and child, an additional adult is typically recommended. Ideally, the observer team will consist of at least three individuals. If only one or two are available, make sure that you have another reliable person to confirm that the findings are legitimate. 1. The patient should be observed at the scene and/or within one hour after the event 2. The patient should be observed again within 48 hours after the event. 3. The patient should be observed again in 24 hours after this event. 4. At each observation the following things should be verified: Is the patient able to recall an event? If no, he/she will not be considered to have a concussion. Does he/she follow instructions appropriately? Does he/she fall prone? Is the patient alert? Does the patient complain of headache? Is the patient nauseous? Is the patient dizzy? Is the patient vomiting? Is the patient stiff? Does he/she remember the event? Is he/she able to answer questions (verbal response)? Does he/she remember objects around him? Does he/she show emotion? Note: Although this is a simple and easy test to perform, it requires a high degree of skill and judgement. This is often overlooked when performing at the scene of the event, or in the emergency room. One way to improve the validity of the test is to add the question, "Can he/she perform
inp = """Section 230 legal precedent cases"""
colorful_inf(inp, gen_len=512, next_line_only=False)
completion done in 29.028940439224243s Section 230 legal precedent cases In December 2006, in American Civil Liberties Union v. Holder, the Supreme Court unanimously held Section 230 of the Communications Decency Act unconstitutional as applied to the plaintiffs. The ACLU challenged Section 230 on the grounds that it effectively immunized internet service providers (ISPs) from liability for third party content posted on their websites, thus granting them virtual immunity for such conduct. In its opinion, the Court explained that "if the First Amendment shields obscenity from regulation, it also shields obscenity displayed on a newspaper's website" because "any such shield must be construed in the light of the special nature and context of the internet." As the Court had determined that obscenity on the internet is not afforded any greater constitutional protection than is obscenity on a printed page, it followed that Section 230 could not act as a shield in the same manner. The decision in American Civil Liberties Union v. American Telephone & Telegraph Company (2005) was quickly followed by a series of lawsuits against Internet intermediaries such as ISPs that either allowed or actively provided access to obscene and libelous content. In April 2007, in Reno v. ACLU, the Supreme Court held Section 230 inapplicable to libel-free speech, ruling that Section 230 immunity did not extend to private individuals posting allegedly libelous comments. In July 2008, in McIntyre v. Ohio Elections Commission, the Supreme Court held that the First Amendment compelled the Court to uphold the right to anonymously criticize elected public officials. In December 2008, in Doe v. 2themart.com, the Court held that an ISP should not be compelled to remove content where it contains false statements about individuals. Subsequent court cases have further developed and clarified Section 230 in the realm of federal regulation of the internet. In particular, the Federal Trade Commission's December 2010, February 2011, and May 2013 reports to Congress recommended changes to Section 230 to address problems with the "uncertain scope" of its immunity, "its limited exceptions, and its unclear impact on various consumer protection laws." In August 2012, in the case of US v. American Library Association, the Court held that library-provided internet access to public-domain information is a public forum and can be regulated on First Amendment grounds. In September 2012, in United States v. Stevens, the Court held that criminal laws requiring someone to have internet access in order to be prosecuted were unconstitutional because such laws prevented someone from constitutionally expressing themselves anonymously on the internet. Decision Section 230 of the Communications Decency Act
There's probably a whole lot more that this model can do right out of the box. If you have data to fine-tune, then I suspect this model would also be fully capable of providing even better results than this too. Definitely exciting times and a very interesting model!
-
GPT-J: 6 Billion parameter open general NLP Transformer
